
1. Large Language Model là gì?
Open AI ChatGPT, Google Gemini, Microsoft Copilot là những sản phẩm công nghệ thông minh đang được sử dụng rộng rãi trên khắp các lĩnh vực trong vài năm gần đây. Bài viết này sẽ giúp giới thiệu sơ lược về mô hình ngôn ngữ lớn (Large Language Model, viết tắt LLM), công nghệ xương sống của những sản phẩm này, cùng một số thuật ngữ và phương pháp sử dụng khi ứng dụng Large Language Model trong thực tế.
Để hiểu về bản chất LLM, hãy xem qua bức tranh tổng quát của lĩnh vực trí tuệ nhân tạo (Artificial Intelligence) ở Hình 1.
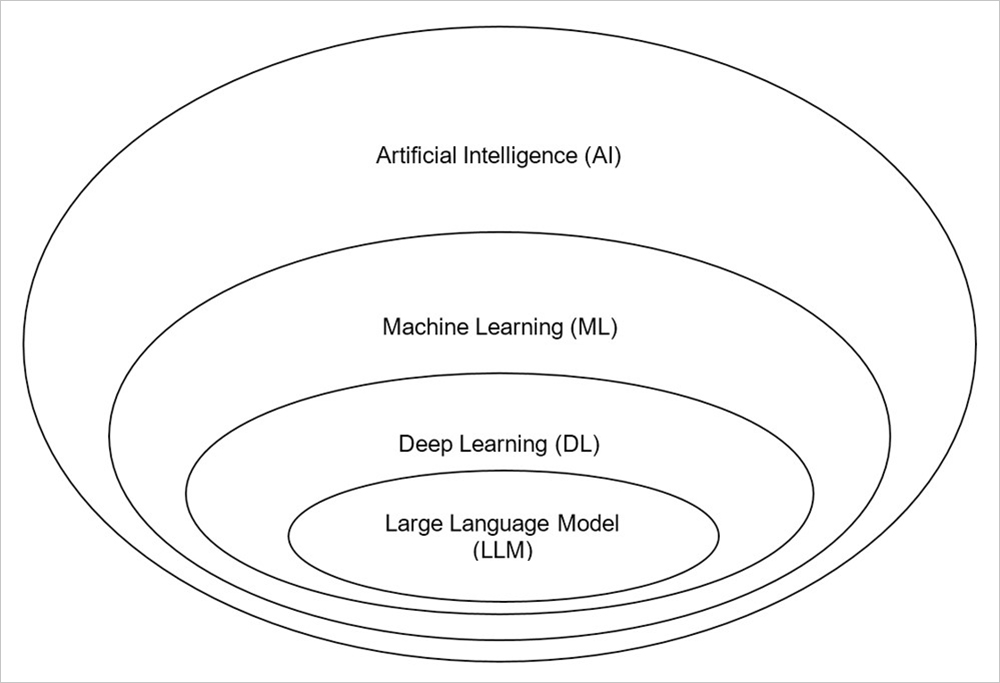
Hình 1: Minh họa về Large Language Model trong Artificial Intelligence
1.1. Artificial Intelligence
Artificial Intelligence (AI) - Trí tuệ nhân tạo là một lĩnh vực trong ngành khoa học máy tính, tập trung vào việc phát triển công nghệ giúp máy tính có thể nhìn nhận, hiểu biết và thực hiện được những công việc một cách thông minh giống như con người [1]. Một số ví dụ về khả năng của AI là nhận diện hình ảnh (Computer Vision), xử lý ngôn ngữ tự nhiên (Natural Language Processing, hay NLP), robotics,...
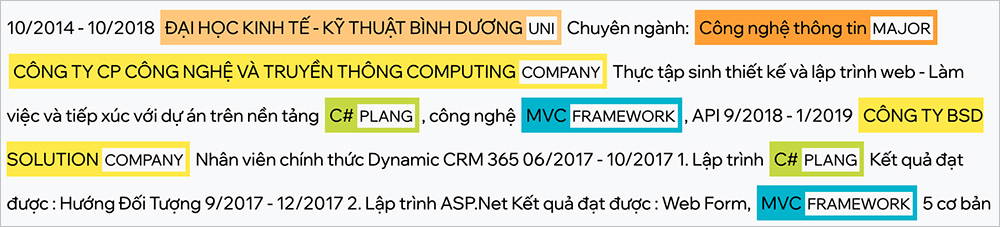
Hình 2: Minh họa ứng dụng AI để nhận diện và trích xuất thực thể trong văn bản (thuộc NLP)
1.2. Machine Learning
Machine Learning (ML) - Học máy là một nhánh phát triển cụ thể trong lĩnh vực AI, khác với lập trình truyền thống, sử dụng máy tính để phân tích và học từ một lượng lớn dữ liệu. Từ đó trong tình huống sử dụng thực tế, máy tính có thể đưa ra quyết định dựa trên dữ liệu đã được học [2]. Một số bài toán tiêu biểu trong ML là Regression (hồi quy), Classification (phân lớp) và Clustering (phân cụm).
Khi mà máy tính được huấn luyện trên lượng lớn dữ liệu đáng tin cậy, máy tính có được cải thiện hơn và có thể phán định cho ra kết quả có độ chính xác cao hơn.
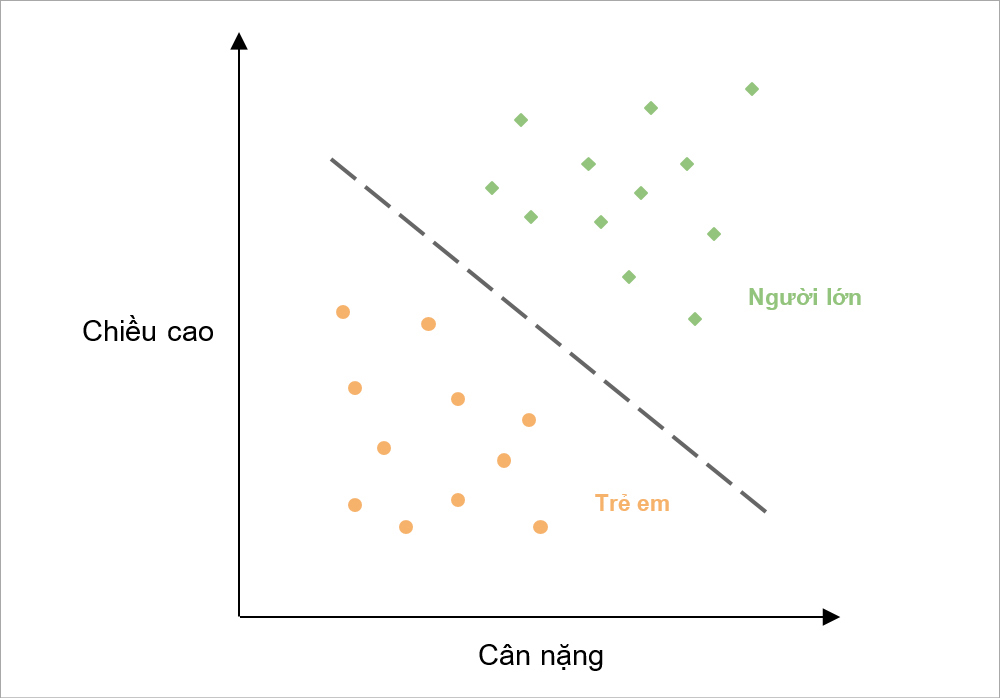
Hình 3: Minh họa cho bài toán phân loại người lớn và trẻ em dựa trên chiều cao và cân nặng (thuộc Classification)
1.3. Deep Learning
Deep Learning (DL) - Học sâu là một nhánh nghiên cứu trong ML, được xây dựng theo kiến trúc mạng nơ-ron (neural network) lấy cảm hứng từ cách hoạt động của bộ não con người.
Đối với ML, dữ liệu để máy tính học cần phải được con người hỗ trợ trích xuất đặc trưng (Feature Extraction) từ trước. Trong khi đó, Deep Learning có thể giúp làm giảm sự phụ thuộc vào con người bằng khả năng tự nhận biết đặc trưng từ dữ liệu [3].
Cũng vì thế mà Deep Learning cần một lượng dữ liệu lớn thì mới hoạt động hiệu quả được.
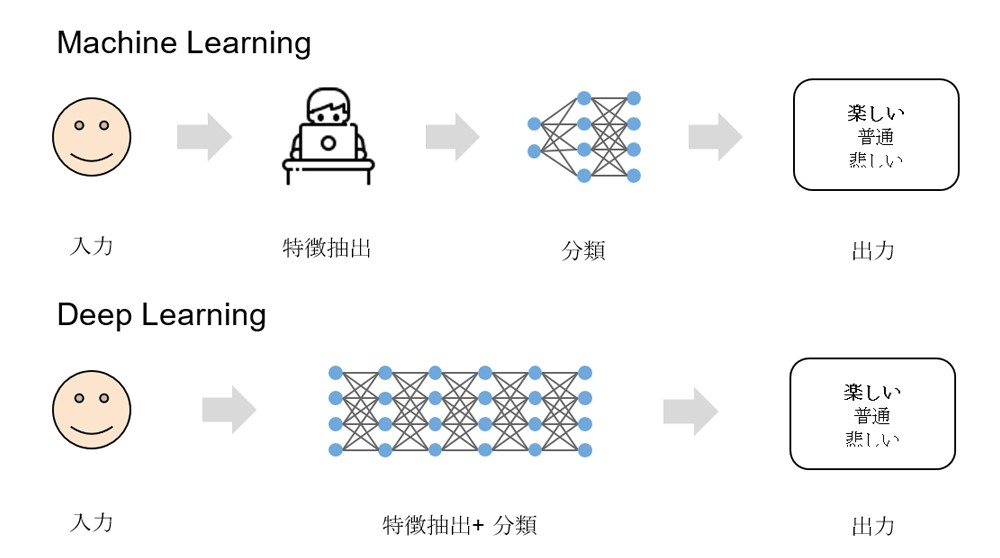
Hình 4: Minh họa sự khác biệt giữa Machine Learning và Deep Learning
1.4. Large Language Model
Để hiểu về LLM, trước hết hãy cùng tìm hiểu định nghĩa mô hình (Model) và mô hình ngôn ngữ (Language Model):
- Model hay AI Model (mô hình AI) có thể hiểu là một chương trình thông minh, sử dụng để thực hiện một tác vụ mà nó đã được huấn luyện và lập trình từ trước [4].
- Language Model là chương trình thông minh chuyên được sử dụng cho các tác vụ xử lý ngôn ngữ tự nhiên (NLP). Nó có khả năng hiểu được cấu trúc, ngữ pháp, ngữ nghĩa của câu văn. Từ đó có thể thực hiện tiên đoán từ tiếp theo, dịch thuật, hay tóm tắt văn bản [5].
LLM là một mô hình DL cực kỳ lớn được huấn luyện trên một lượng dữ liệu văn bản khổng lồ. Nó là một loại Generative AI (AI tạo sinh) có thể dự đoán từ ngữ trong câu, hiểu, thực hiện các tác vụ về ngôn ngữ và tự sinh trả lời câu hỏi thông qua tương tác trực tiếp bằng ngôn ngữ tự nhiên của con người [6].
LLM có khả năng thực hiện các tác vụ chung, ví dụ như:
- Làm chatbot, hỏi đáp kiến thức
- Tạo văn bản và tóm tắt
- Hỗ trợ dịch thuật
- Phân loại văn bản
- Phân tích cảm xúc
- Làm công cụ hỗ trợ tìm kiếm
- Phát hiện bất thường
Ngoài ra, LLM còn được ứng dụng cụ thể hơn trên rất nhiều lĩnh vực, tiêu biểu như:
- Phát triển phần mềm: Hỗ trợ viết code, tạo dữ liệu.
- Y học: Nghiên cứu về gen, hỗ trợ kê đơn thuốc.
- Tài chính: Phân tích thị trường, tạo báo cáo.
- Chăm sóc khách hàng: Chatbot, hỗ trợ tiếp thị sản phẩm.
- Tuyển dụng: Sàng lọc và đánh giá ứng viên.
2. Thuật ngữ trong LLM
“Mô hình Llama 3.1 405B (405 tỷ parameter) vừa được Meta cho ra mắt.”
“GPT trong ChatGPT là gì?”
“OpenAI công bố mô hình GPT-4-turbo hỗ trợ lên đến 128K token.”
Hãy cùng giải mã các thuật ngữ phổ biến khi sử dụng và làm việc với LLM.
2.1. Parameter
Như đã nêu ra ở phần trên, LLM là mô hình DL lớn, chứa đựng một mạng nơ-ron cực kỳ lớn và phức tạp bên trong. Parameter có thể được hiểu là liên kết giữa các nơ-ron trong mạng này, được biểu diễn ở dạng số. Khi mô hình được huấn luyện, những con số (liên kết) này sẽ thay đổi để thích ứng với dữ liệu được học. Số lượng parameter càng nhiều thì mô hình càng lớn, và đa số các LLM hiện nay thường có lượng parameter lên đến hàng tỷ (viết tắt là B) [7].
Một vài ví dụ về số lượng parameter của các mô hình gia tăng qua từng năm:
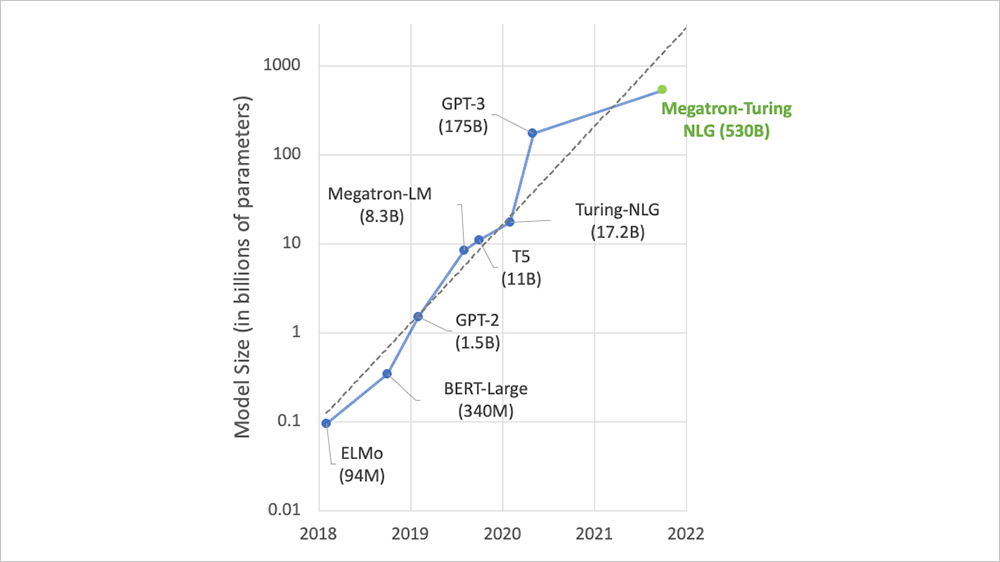
Hình 5: Mô tả lượng parameter của một số LLM qua từng năm
2.2. Foundation model
Khi các mô hình đã được huấn luyện đến một cột mốc nhất định, chúng dừng tại đó và có thể được xác định là Foundation Model (còn được gọi là Base Model hay Pre-trained Model). Cũng đồng nghĩa là các parameter của chúng được đóng băng và cố định tại thời điểm đó [8]. Ví dụ gemma2 là một Foundation Model được phát triển bởi Google.
Foundation Model có thể được đưa vào sử dụng trong thực tế, hay có thể được tiếp tục huấn luyện thêm cho một công việc cụ thể (Fine-tuning).
Có thể ví Foundation Model như một cậu sinh viên mới tốt nghiệp. Các kiến thức ở đại học (dữ liệu) đã được tích lũy (huấn luyện) đến mốc là thời điểm mới ra trường. Một công ty có thể nhận sinh viên này về để làm việc (sử dụng trực tiếp). Nhưng cậu sinh viên này chưa có nhiều kinh nghiệm làm việc, công ty sẽ cho cậu tham gia các khóa training nội bộ để học về quy trình làm việc cũng như cải thiện các kỹ năng trong công việc (Fine-tuning).
Đến đây thì cũng có thể giải thích được ý nghĩa của “GPT” trong ChatGPT như sau:
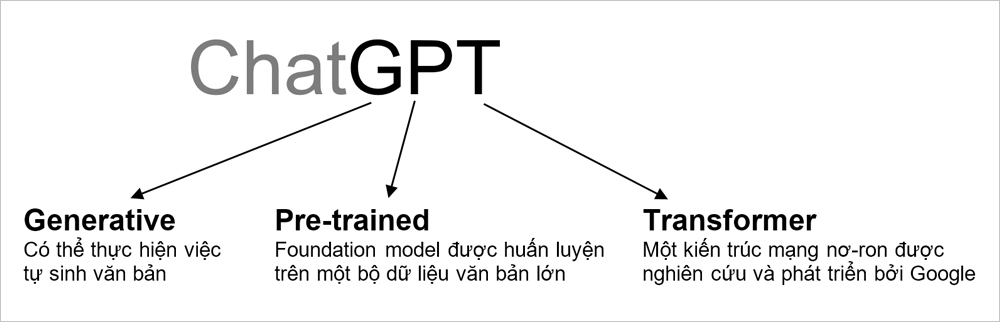
Hình 6: Ý nghĩa của “GPT” trong ChatGPT
2.3. Token & tokenization
Token là một từ, một cụm các ký tự hay một cụm từ (tùy vào ngôn ngữ hay loại ký tự) được phân tách từ đoạn văn bản. Trong quá trình huấn luyện, LLM phân tích và hiểu được mối quan hệ ngữ nghĩa của các token này. Sau đó trong quá trình sử dụng, LLM có thể tự sinh ra chuỗi token dựa trên văn bản đầu vào [9].
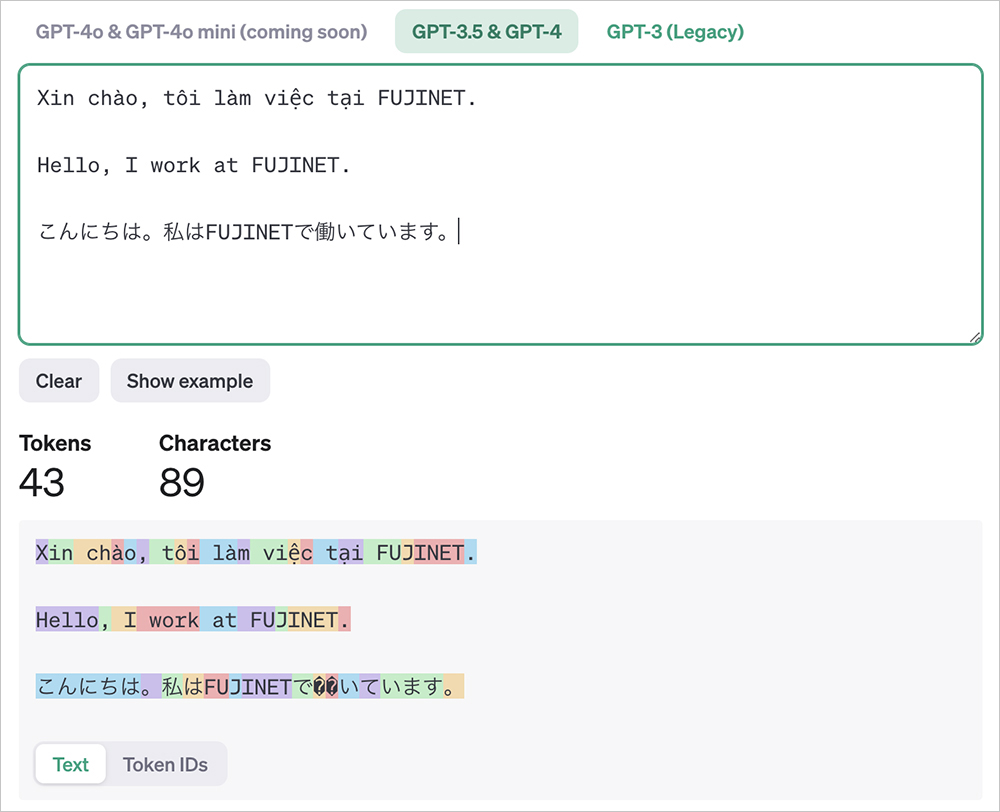
Hình 7: Minh họa cho các token trong một câu (độ dài token biểu thị bởi màu xen kẽ lẫn nhau)
Với mỗi loại LLM thì chúng có giới hạn về lượng token nhận vào từ input và số lượng token có thể tự sinh khác nhau:
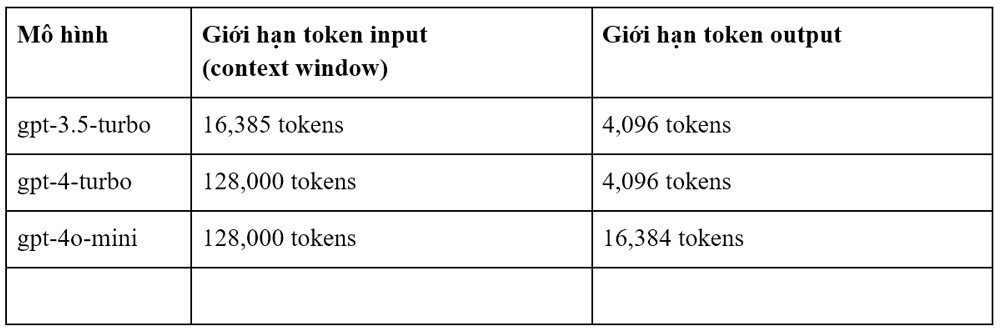
Bảng 1: Mô tả số lượng input/output token giới hạn của một số mô hình
Nguồn: https://platform.openai.com/docs/models
Tokenization bao gồm việc chuyển văn bản input thành các con số để LLM có thể hiểu được, sau đó chuyển kết quả output từ các con số thành văn bản mà con người có thể hiểu được. Hai công việc này được gọi là encoding và decoding [10].
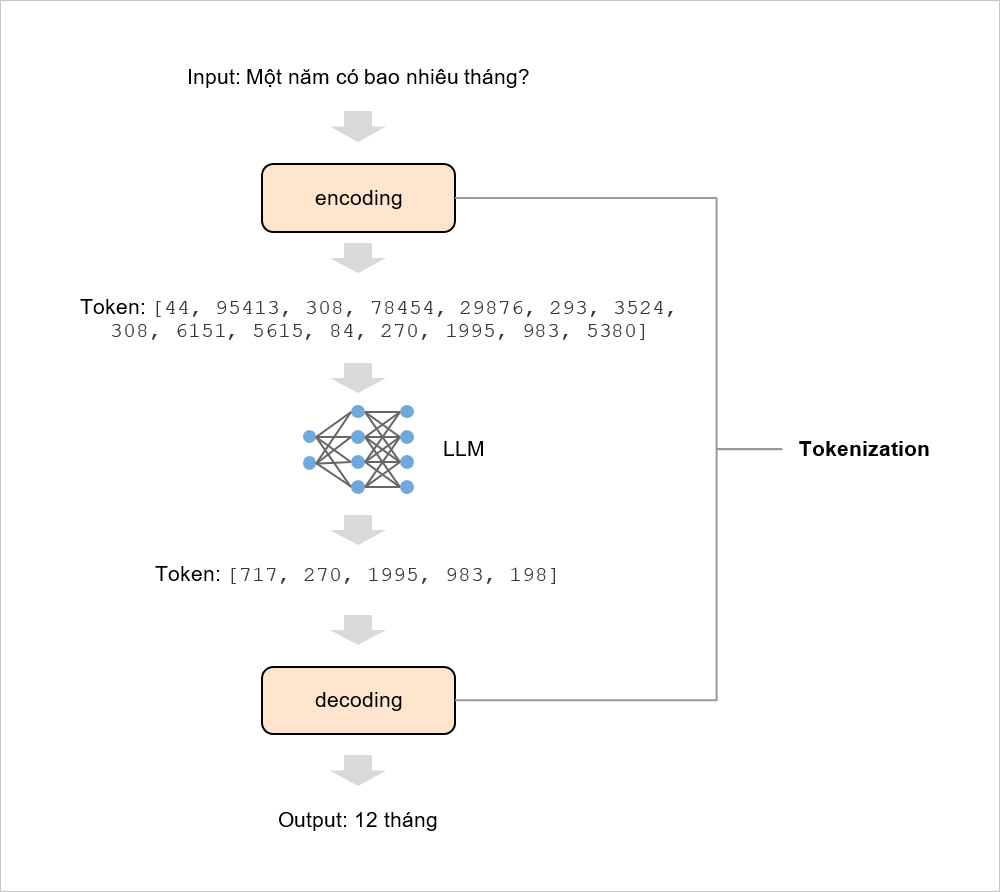
Hình 8: Minh họa cho Tokenization trong LLM
Đối với mỗi loại LLM khác nhau, có thể chúng sẽ có phương pháp Tokenization khác nhau. Cũng có thể ví giống như với con người, mỗi người có thể nhìn nhận, tư duy và quyết định về cùng một vấn đề theo nhiều cách khác nhau.
2.4. Hallucination
Hallucination (ảo giác) là hiện tượng LLM cho ra kết quả không đúng với thực tế, là khi nó cố gắng tự sinh đoạn văn bản nằm ngoài phạm vi dữ liệu mà nó được huấn luyện. Vậy nên khi ứng dụng LLM trong hệ thống thực tế, cần phải chú ý đến vấn đề này để đảm bảo tính đúng đắn cũng như độ tin cậy của sản phẩm cuối cùng [11].
Ví dụ: LLM được huấn luyện với dữ liệu trước năm 2021 cố gắng trả lời cho một câu hỏi về sự kiện diễn ra vào năm 2024.
Để tránh hiện tượng Hallucination ở LLM, người ta có thể sử dụng những tham số mô hình là temperature, top_p, top_k hoặc logit_bias. Trong đó, tham số temperature là một tham số cơ bản và thường được sử dụng để can thiệp vào cách mà LLM tự sinh văn bản.
Ví dụ đối với mô hình của OpenAI, temperature có miền giá trị từ 0 đến 2. Giá trị càng gần 2 thì output càng ngẫu nhiên và đa dạng, phù hợp với việc sáng tạo nội dung. Ngược lại, càng gần 0 thì output càng tất định và có căn cứ dựa trên dữ liệu đã được học, phù hợp với việc hỏi đáp kiến thức đòi hỏi sự chính xác [12].
3. Phương pháp sử dụng LLM
Để ứng dụng LLM vào thực tế, có nhiều phương pháp sử dụng tùy theo mức độ phức tạp, chi phí phát triển và sử dụng. Bài viết này sẽ đề cập đến 4 phương pháp được thể hiện ở biểu đồ dưới đây:
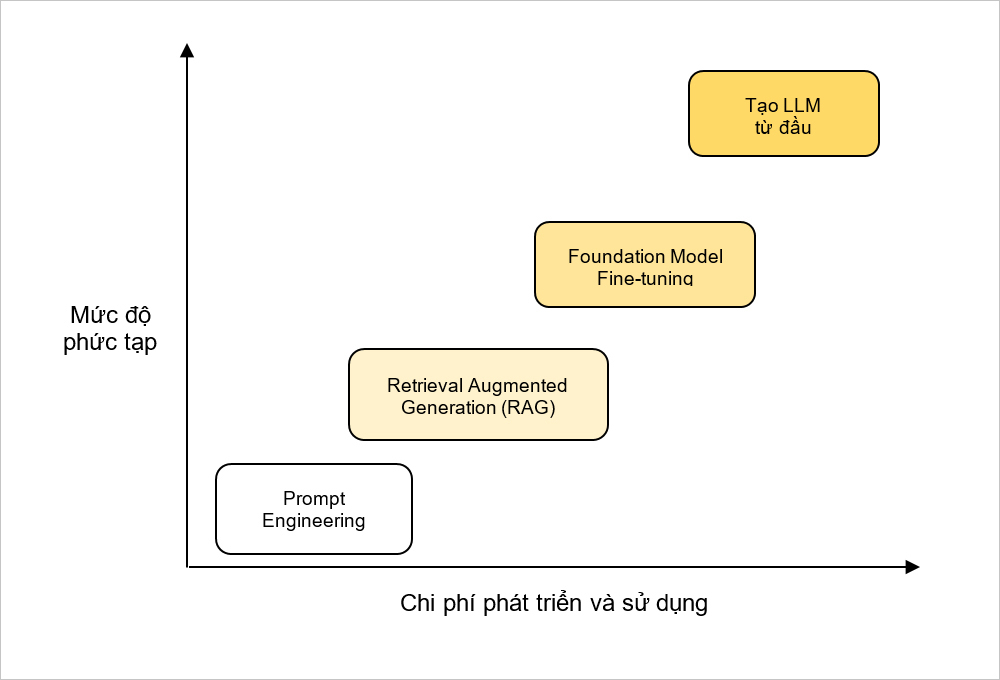
Hình 9: Biểu đồ mô tả các phương pháp sử dụng LLM dựa trên mức độ phức tạp, chi phí phát triển và sử dụng
Nguồn: https://notebooks.databricks.com/demos/llm-rag-chatbot/index.html
3.1. Prompt Engineering
Prompt Engineering là phương pháp cơ bản nhất và phổ biến nhất. Dễ hiểu nhất là sử dụng ChatGPT để đặt câu hỏi và nhận lại câu trả lời. Việc đặt câu hỏi làm sao cho phù hợp để nhận được câu trả lời mong muốn được gọi là “Prompt Engineering” [13].
Có rất nhiều phương pháp trong Prompt Engineering, một số ví dụ tiêu biểu như [14]:
- Đặt 1 câu hỏi duy nhất để nhận câu trả lời (Zero-shot prompting)
- Đặt 1 câu hỏi bao gồm những bước cần thực hiện để nhận câu trả lời (Few-shot prompting)
- Đặt nhiều câu hỏi và câu trả lời mẫu nhằm tạo lý luận cho LLM đưa ra câu trả lời cuối cùng (Chain-of-thought Prompting)
3.2. Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) là một phương pháp sử dụng LLM kết hợp với dữ liệu chưa được huấn luyện trên nó. Trước khi đặt câu hỏi, người ta sẽ cung cấp thêm ngữ cảnh và đặt câu hỏi trên ngữ cảnh đó, buộc LLM tự sinh câu trả lời phù hợp với ngữ cảnh. Với phương pháp sử dụng RAG thì không cần tốn chi phí huấn luyện lại mô hình LLM [15].
Có thể lấy ví dụ như việc một học sinh (LLM) làm bài thi mở được phép sử dụng tài liệu. Dựa trên câu hỏi (input), mà học sinh đó sẽ tra tài liệu (ngữ cảnh) để đưa ra câu trả lời phù hợp (output).
Phương pháp này được xem là khá hiệu quả và dễ tiếp cận với những doanh nghiệp vừa và nhỏ hiện nay.
3.3. Foundation Model Fine-tuning
Foundation Model Fine-tuning như đã đề cập, là một phương pháp huấn luyện LLM có sẵn trên bộ dữ liệu đặc thù. Phương pháp này thường được sử dụng khi mong muốn gia tăng mức độ hiểu biết chuyên sâu hơn về nghiệp vụ cụ thể. LLM sau khi được huấn luyện sẽ trở nên chuyên biệt cho riêng nghiệp vụ của dữ liệu đó [16].
Tuy nhiên để thực hiện được thì cần phải đáp ứng được cả về dữ liệu lẫn hạ tầng phần cứng:
- Dữ liệu: Phải đủ lớn, có chất lượng cao và đáng tin cậy.
- Hạ tầng phần cứng: Phần cứng đủ mạnh để đáp ứng việc huấn luyện mô hình. Nghĩa là sức mạnh hạ tầng phải tỷ lệ thuận với độ lớn mô hình.
3.4. Tạo LLM từ đầu
Tạo LLM từ đầu là phương pháp sử dụng có mức độ phức tạp cao và tốn nhiều chi phí nhất. Khác với Fine-tuning là có Foundation Model đã được huấn luyện và chỉ cần mở rộng thêm dữ liệu, việc Tạo LLM từ đầu đòi hỏi bao gồm lượng dữ liệu nhiều hơn rất nhiều, hạ tầng phần cứng mạnh, hiểu biết về kỹ thuật xây dựng mô hình, và rất nhiều các tiêu chí khác [17].
Ví dụ về một số thông số về chi phí của mô hình Llama3 do Meta phát triển:
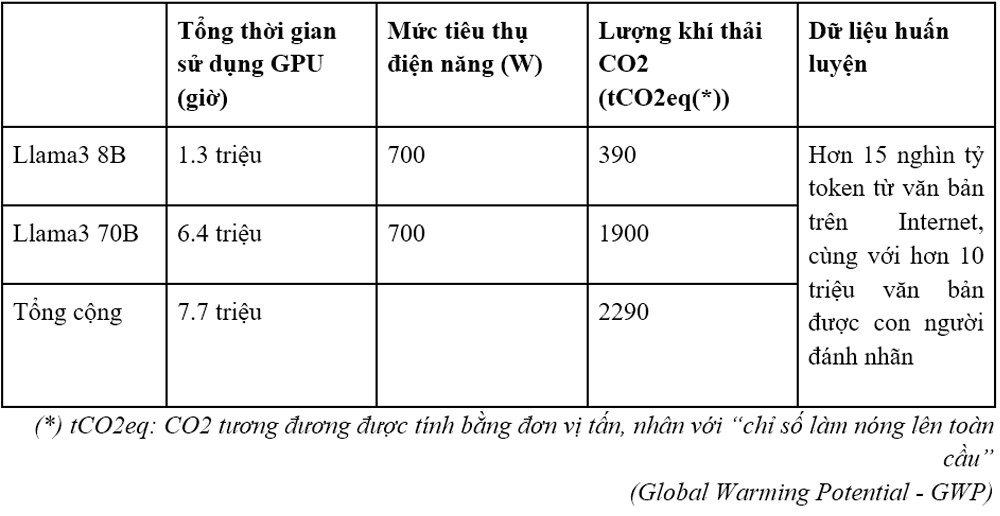
Bảng 2: Mô tả chi phí tạo mô hình Llama3
Nguồn: https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md
Nguồn tham khảo:
[1] AWS. (2024). What is Artificial Intelligence?. https://aws.amazon.com/what-is/artificial-intelligence/.
[2] AWS. (2024). What is Machine Learning?. https://aws.amazon.com/what-is/machine-learning.
[3] Google. (2024). What's the difference between deep learning, machine learning, and artificial intelligence?. https://cloud.google.com/discover/deep-learning-vs-machine-learning.
[4] IBM. (2024). What Is an AI Model?. https://www.ibm.com/topics/ai-model.
[5] H2O. (2024). Language Modeling https://h2o.ai/wiki/language-modeling/.
[6] AWS. (2024). What are Large Language Models?. https://aws.amazon.com/what-is/large-language-model/.
[7] Andreas Stöffelbauer. (2023). How Large Language Models Work. https://medium.com/data-science-at-microsoft/how-large-language-models-work-91c362f5b78f.
[8] Tensor. (2023). Glossary of LLM and Generative AI. https://medium.com/@shuchaobi/glossary-of-llm-and-generative-ai-b3111da41da7.
[9] Microsoft. (2024). Understanding tokens. https://learn.microsoft.com/en-us/dotnet/ai/conceptual/understanding-tokens.
[10] MistralAI. (2024). Tokenization. https://docs.mistral.ai/guides/tokenization/.
[11] Deval Shah. (2023). The Beginner’s Guide to Hallucinations in Large Language Models. https://www.lakera.ai/blog/guide-to-hallucinations-in-large-language-models.
[12] OpenAI. (2024). API Reference. https://platform.openai.com/docs/api-reference/chat/create.
[13] AWS. (2024). What is Prompt Engineering?. https://aws.amazon.com/what-is/prompt-engineering/.
[14] Pranab Sahoo et al. (2024). A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications. https://arxiv.org/pdf/2402.07927.
[15] Databricks. (2024). What Is Retrieval Augmented Generation, or RAG?. https://www.databricks.com/glossary/retrieval-augmented-generation-rag.
[16] Turing. (2024). Fine-Tuning LLMs: Overview, Methods, and Best Practices. https://www.turing.com/resources/finetuning-large-language-models.
[17] Anil Prasad. (2023). Understanding cost, options and Technical steps to build LLM from scratch. https://medium.com/@anilAmbharii/understanding-cost-options-and-technical-steps-to-build-llm-from-scratch-d68cb9ba7bd9.
